腾讯云大数据型实例族 之 大数据型 D2 实例
腾讯云大数据型实例搭载海量存储资源,具有高吞吐特点,适合 Hadoop 分布式计算、海量日志处理、分布式文件系统和大型数据仓库等吞吐密集型应用
大数据型 D2
大数据型 D2 实例是最新一代的大数据型实例,配备搭载高吞吐、海量存储资源,最高可搭载 144T SATA HDD 本地存储, 适合 Hadoop 分布式计算、并行数据处理等吞吐密集型业务使用。
使用场景
-
Hadoop MapReduce/HDFS/Hive/HBase 等分布式计算
-
Elasticsearch、日志处理和大型数据仓库等业务场景设计
-
互联网行业、金融行业等有大数据计算与存储分析需求的行业客户,进行海量数据存储和计算的业务场景
实例特点
-
2.4GHz Intel® Xeon® Skylake 6148 处理器,DDR4 内存
-
实例最高搭载12块12TB本地硬盘,配备最高144TB的基于 HDD 的本地存储
-
单盘顺序读吞吐能力220+MB/s,顺序写吞吐能力220+MB/s(128KB块大小,32深度)
-
整机吞吐能力最高可达2.8GB/s(128KB块大小,32深度)
-
低至2ms - 5ms读写延时
-
-
更大的实例规格,D2.19XLARGE320,最高提供76vCPU 和320GB内存
-
本地存储单价低至 S2 的1/10,与 IDC 自建 Hadoop 集群拥有相近的总成本
-
处理器与内存配比为1:4,为大数据场景设计
实例要求
-
大数据型 D2 实例的数据盘是本地硬盘,有丢失数据的风险(例如宿主机宕机时),如果您的应用不能做到数据可靠性的架构,我们强烈建议您使用可以选择云硬盘作为数据盘的实例。
-
若本地硬盘损坏后,需要您进行云服务器实例关闭操作后,我们才能够进行本地硬盘替换。
-
若云服务器实例已经宕机,我们会告知您并进行维修操作。
-
-
大数据型 D2 实例可以用作包年包月实例和按量计费实例。
-
仅支持在私有网络中启动 D2 实例。
-
D2 实例不支持调整配置。
-
D2 实例支持购买配置,请参阅下方实例规格。
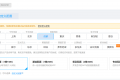
|
规格 |
vCPU |
内存 (GB) |
网络 收发包 (pps) |
队列数 |
内网 带宽能力 (Gbps) |
主频 |
备注 |
|
D2.2XLARGE32 |
8 |
32 |
80万 |
2 |
3.0 |
2.4GHz |
搭载1块11176GB SATA HDD 本地硬盘 |
|
D2.4XLARGE64 |
16 |
64 |
150万 |
4 |
6.0 |
2.4GHz |
搭载2块11176GB SATA HDD 本地硬盘 |
|
D2.6XLARGE96 |
24 |
96 |
200万 |
6 |
8.0 |
2.4GHz |
搭载3块11176GB SATA HDD 本地硬盘 |
|
D2.8XLARGE128 |
32 |
128 |
250万 |
8 |
11.0 |
2.4GHz |
搭载4块11176GB SATA HDD 本地硬盘 |
|
D2.16XLARGE256 |
64 |
256 |
500万 |
16 |
22.0 |
2.4GHz |
搭载8块11176GB SATA HDD 本地硬盘 |
|
D2.19XLARGE320 |
76 |
320 |
600万 |
16 |
25.0 |
2.4GHz |
搭载12块11176GB SATA HDD 本地硬盘 |
本文地址:https://www.buytxy.com/product/59.html